Benchmarking ID generation libraries in Python
by Elias Hernandis • Published March 6, 2023 • Tagged benchmark, performance, python
Last week I wrote about the different features that can be considered when selecting an format for IDs. We looked at different versions of UUIDs, with varying length, randomness, ordering and serialization capabilities.
Another important factor to consider is performance, especially if you find yourself looking at these IDs for their sorting or randomness properties, which means you are probably generating a lot of IDs.
There are two operations which happen all the time when dealing with IDs in your Python code:
- ID generation, that is, coming up with a new unique ID. Some systems need to draw random bytes from the OS, while others need to learn the time or about partitioning metadata.
- ID serialization and deserialization, i.e. converting an ID into a primitive data type (a
stringorint). Some formats work with native datatypes already while others work with custom objects that wrap a bunch of raw bytes.
Chances are you are doing or will be doing these operations millions of times per day and they'll likely be part of almost any process carried out by your application. We're benchmarking them both and sharing the results so you have one more data point to choose the ID generation strategy that best suits your needs.
How performance benchmarks were set up
You can reproduce the experiments using the code in this GitHub repo. It also contains more info about where the experiments were run in addition to the raw result data.
We used the pytest-benchmark module, because it makes sure runs are long enough to be measurable, and in general takes care of most artifacts that would arise if we were to roll our own benchmarking suite.
The contenders are the following:
- Python's own UUID module to generate v4 UUIDs with
uuid.uuid4(). - KSUID implementations:
- svix-ksuid with the standard second-precision implementation
- cyksuid
- ulid-py
- timeflake
- snowflake-id
- cuid2
We measured generation speed for all of them, and deserialization (converting from a string to the library's own internal depresentation) where it made sense (e.g. snowflake IDs are already integers so there's not much serialization / deserialization to do there).
Results
| Name | Mean (ns) | Speedup | StdDev (ns) |
|---|---|---|---|
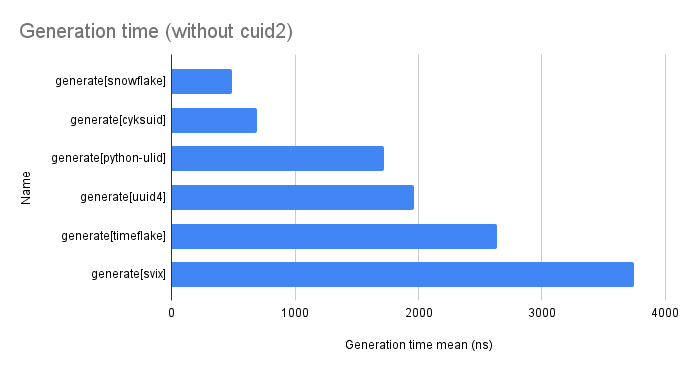
| generate[snowflake] | 492 | 1 | 47 |
| generate[cyksuid] | 696 | 1 | 119 |
| generate[python-ulid] | 1720 | 3 | 240 |
| generate[uuid4] | 1961 | 4 | 120 |
| generate[timeflake] | 2637 | 5 | 452 |
| generate[svix] | 3747 | 8 | 685 |
| generate[cuid2] | 317833 | 646 | 4876 |
As you can see cuid2 is way slower than the rest.
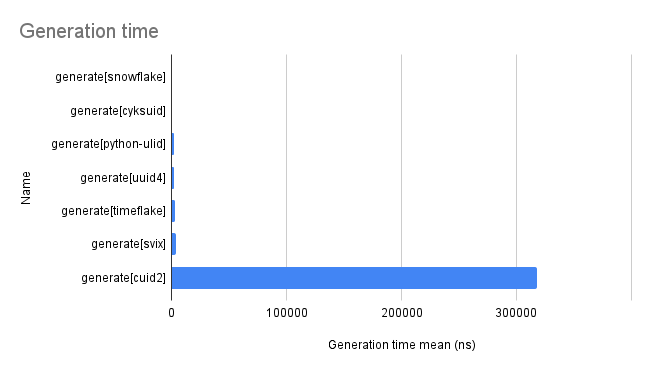
Here's a chart without it so you can compare the rest better.
As for deserialization, here are the results
| Name | Mean (ns) | Speedup | StdDev (ns) |
|---|---|---|---|
| parse[cyksuid] | 478 | 1 | 88 |
| parse[uuid4] | 1373 | 3 | 257 |
| parse[snowflake] | 1543 | 3 | 370 |
| parse[timeflake] | 3867 | 8 | 334 |
| parse[svix] | 23713 | 50 | 952 |
And a chart to better visualize them

Conclusion
While performance is not the only factor to consider, and this quick analysis certainly doesn't tell the full picture (e.g. it doesn't look at how these formats perform in databases), I think this serves as a good initial approach if you need to consider how these libraries perform.